 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeOptiSQL: Executable SQL Generation from Optical Tokens
Jan 21, 2026Executable SQL generation is typically studied in text-to-SQL settings, where tables are provided as fully linearized textual schemas and contents. While effective, this formulation assumes access to structured text and incurs substantial token overhead, which is misaligned with many real-world scenarios where tables appear as visual artifacts in documents or webpages. We investigate whether compact optical representations can serve as an efficient interface for executable semantic parsing. We present OptiSQL, a vision-driven framework that generates executable SQL directly from table images and natural language questions using compact optical tokens. OptiSQL leverages an OCR-oriented visual encoder to compress table structure and content into a small set of optical tokens and fine-tunes a pretrained decoder for SQL generation while freezing the encoder to isolate representation sufficiency. Experiments on a visualized version of Spider 2.0-Snow show that OptiSQL retains strong execution accuracy while reducing table input tokens by an order of magnitude. Robustness analyses further demonstrate that optical tokens preserve essential structural information under visual perturbations.
DeepFeature: Iterative Context-aware Feature Generation for Wearable Biosignals
Dec 09, 2025Biosignals collected from wearable devices are widely utilized in healthcare applications. Machine learning models used in these applications often rely on features extracted from biosignals due to their effectiveness, lower data dimensionality, and wide compatibility across various model architectures. However, existing feature extraction methods often lack task-specific contextual knowledge, struggle to identify optimal feature extraction settings in high-dimensional feature space, and are prone to code generation and automation errors. In this paper, we propose DeepFeature, the first LLM-empowered, context-aware feature generation framework for wearable biosignals. DeepFeature introduces a multi-source feature generation mechanism that integrates expert knowledge with task settings. It also employs an iterative feature refinement process that uses feature assessment-based feedback for feature re-selection. Additionally, DeepFeature utilizes a robust multi-layer filtering and verification approach for robust feature-to-code translation to ensure that the extraction functions run without crashing. Experimental evaluation results show that DeepFeature achieves an average AUROC improvement of 4.21-9.67% across eight diverse tasks compared to baseline methods. It outperforms state-of-the-art approaches on five tasks while maintaining comparable performance on the remaining tasks.
Detecting and Mitigating Insertion Hallucination in Video-to-Audio Generation
Oct 09, 2025Video-to-Audio generation has made remarkable strides in automatically synthesizing sound for video. However, existing evaluation metrics, which focus on semantic and temporal alignment, overlook a critical failure mode: models often generate acoustic events, particularly speech and music, that have no corresponding visual source. We term this phenomenon Insertion Hallucination and identify it as a systemic risk driven by dataset biases, such as the prevalence of off-screen sounds, that remains completely undetected by current metrics. To address this challenge, we first develop a systematic evaluation framework that employs a majority-voting ensemble of multiple audio event detectors. We also introduce two novel metrics to quantify the prevalence and severity of this issue: IH@vid (the fraction of videos with hallucinations) and IH@dur (the fraction of hallucinated duration). Building on this, we propose Posterior Feature Correction, a novel training-free inference-time method that mitigates IH. PFC operates in a two-pass process: it first generates an initial audio output to detect hallucinated segments, and then regenerates the audio after masking the corresponding video features at those timestamps. Experiments on several mainstream V2A benchmarks first reveal that state-of-the-art models suffer from severe IH. In contrast, our PFC method reduces both the prevalence and duration of hallucinations by over 50\% on average, without degrading, and in some cases even improving, conventional metrics for audio quality and temporal synchronization. Our work is the first to formally define, systematically measure, and effectively mitigate Insertion Hallucination, paving the way for more reliable and faithful V2A models.
ContextAgent: Context-Aware Proactive LLM Agents with Open-World Sensory Perceptions
May 20, 2025Recent advances in Large Language Models (LLMs) have propelled intelligent agents from reactive responses to proactive support. While promising, existing proactive agents either rely exclusively on observations from enclosed environments (e.g., desktop UIs) with direct LLM inference or employ rule-based proactive notifications, leading to suboptimal user intent understanding and limited functionality for proactive service. In this paper, we introduce ContextAgent, the first context-aware proactive agent that incorporates extensive sensory contexts to enhance the proactive capabilities of LLM agents. ContextAgent first extracts multi-dimensional contexts from massive sensory perceptions on wearables (e.g., video and audio) to understand user intentions. ContextAgent then leverages the sensory contexts and the persona contexts from historical data to predict the necessity for proactive services. When proactive assistance is needed, ContextAgent further automatically calls the necessary tools to assist users unobtrusively. To evaluate this new task, we curate ContextAgentBench, the first benchmark for evaluating context-aware proactive LLM agents, covering 1,000 samples across nine daily scenarios and twenty tools. Experiments on ContextAgentBench show that ContextAgent outperforms baselines by achieving up to 8.5% and 6.0% higher accuracy in proactive predictions and tool calling, respectively. We hope our research can inspire the development of more advanced, human-centric, proactive AI assistants.
An LLM-Empowered Low-Resolution Vision System for On-Device Human Behavior Understanding
May 03, 2025The rapid advancements in Large Vision Language Models (LVLMs) offer the potential to surpass conventional labeling by generating richer, more detailed descriptions of on-device human behavior understanding (HBU) in low-resolution vision systems, such as depth, thermal, and infrared. However, existing large vision language model (LVLM) approaches are unable to understand low-resolution data well as they are primarily designed for high-resolution data, such as RGB images. A quick fixing approach is to caption a large amount of low-resolution data, but it requires a significant amount of labor-intensive annotation efforts. In this paper, we propose a novel, labor-saving system, Llambda, designed to support low-resolution HBU. The core idea is to leverage limited labeled data and a large amount of unlabeled data to guide LLMs in generating informative captions, which can be combined with raw data to effectively fine-tune LVLM models for understanding low-resolution videos in HBU. First, we propose a Contrastive-Oriented Data Labeler, which can capture behavior-relevant information from long, low-resolution videos and generate high-quality pseudo labels for unlabeled data via contrastive learning. Second, we propose a Physical-Knowledge Guided Captioner, which utilizes spatial and temporal consistency checks to mitigate errors in pseudo labels. Therefore, it can improve LLMs' understanding of sequential data and then generate high-quality video captions. Finally, to ensure on-device deployability, we employ LoRA-based efficient fine-tuning to adapt LVLMs for low-resolution data. We evaluate Llambda using a region-scale real-world testbed and three distinct low-resolution datasets, and the experiments show that Llambda outperforms several state-of-the-art LVLM systems up to $40.03\%$ on average Bert-Score.
OpenTCM: A GraphRAG-Empowered LLM-based System for Traditional Chinese Medicine Knowledge Retrieval and Diagnosis
Apr 28, 2025Traditional Chinese Medicine (TCM) represents a rich repository of ancient medical knowledge that continues to play an important role in modern healthcare. Due to the complexity and breadth of the TCM literature, the integration of AI technologies is critical for its modernization and broader accessibility. However, this integration poses considerable challenges, including the interpretation of obscure classical Chinese texts and the modeling of intricate semantic relationships among TCM concepts. In this paper, we develop OpenTCM, an LLM-based system that combines a domain-specific TCM knowledge graph and Graph-based Retrieval-Augmented Generation (GraphRAG). First, we extract more than 3.73 million classical Chinese characters from 68 gynecological books in the Chinese Medical Classics Database, with the help of TCM and gynecology experts. Second, we construct a comprehensive multi-relational knowledge graph comprising more than 48,000 entities and 152,000 interrelationships, using customized prompts and Chinese-oriented LLMs such as DeepSeek and Kimi to ensure high-fidelity semantic understanding. Last, we integrate OpenTCM with this knowledge graph, enabling high-fidelity ingredient knowledge retrieval and diagnostic question-answering without model fine-tuning. Experimental evaluations demonstrate that our prompt design and model selection significantly improve knowledge graph quality, achieving a precision of 98. 55% and an F1 score of 99. 55%. In addition, OpenTCM achieves mean expert scores of 4.5 in ingredient information retrieval and 3.8 in diagnostic question-answering tasks, outperforming state-of-the-art solutions in real-world TCM use cases.
MME-Unify: A Comprehensive Benchmark for Unified Multimodal Understanding and Generation Models
Apr 07, 2025Existing MLLM benchmarks face significant challenges in evaluating Unified MLLMs (U-MLLMs) due to: 1) lack of standardized benchmarks for traditional tasks, leading to inconsistent comparisons; 2) absence of benchmarks for mixed-modality generation, which fails to assess multimodal reasoning capabilities. We present a comprehensive evaluation framework designed to systematically assess U-MLLMs. Our benchmark includes: Standardized Traditional Task Evaluation. We sample from 12 datasets, covering 10 tasks with 30 subtasks, ensuring consistent and fair comparisons across studies." 2. Unified Task Assessment. We introduce five novel tasks testing multimodal reasoning, including image editing, commonsense QA with image generation, and geometric reasoning. 3. Comprehensive Model Benchmarking. We evaluate 12 leading U-MLLMs, such as Janus-Pro, EMU3, VILA-U, and Gemini2-flash, alongside specialized understanding (e.g., Claude-3.5-Sonnet) and generation models (e.g., DALL-E-3). Our findings reveal substantial performance gaps in existing U-MLLMs, highlighting the need for more robust models capable of handling mixed-modality tasks effectively. The code and evaluation data can be found in https://mme-unify.github.io/.
SHADE-AD: An LLM-Based Framework for Synthesizing Activity Data of Alzheimer's Patients
Mar 03, 2025



Alzheimer's Disease (AD) has become an increasingly critical global health concern, which necessitates effective monitoring solutions in smart health applications. However, the development of such solutions is significantly hindered by the scarcity of AD-specific activity datasets. To address this challenge, we propose SHADE-AD, a Large Language Model (LLM) framework for Synthesizing Human Activity Datasets Embedded with AD features. Leveraging both public datasets and our own collected data from 99 AD patients, SHADE-AD synthesizes human activity videos that specifically represent AD-related behaviors. By employing a three-stage training mechanism, it broadens the range of activities beyond those collected from limited deployment settings. We conducted comprehensive evaluations of the generated dataset, demonstrating significant improvements in downstream tasks such as Human Activity Recognition (HAR) detection, with enhancements of up to 79.69%. Detailed motion metrics between real and synthetic data show strong alignment, validating the realism and utility of the synthesized dataset. These results underscore SHADE-AD's potential to advance smart health applications by providing a cost-effective, privacy-preserving solution for AD monitoring.
Tri-Ergon: Fine-grained Video-to-Audio Generation with Multi-modal Conditions and LUFS Control
Dec 29, 2024Video-to-audio (V2A) generation utilizes visual-only video features to produce realistic sounds that correspond to the scene. However, current V2A models often lack fine-grained control over the generated audio, especially in terms of loudness variation and the incorporation of multi-modal conditions. To overcome these limitations, we introduce Tri-Ergon, a diffusion-based V2A model that incorporates textual, auditory, and pixel-level visual prompts to enable detailed and semantically rich audio synthesis. Additionally, we introduce Loudness Units relative to Full Scale (LUFS) embedding, which allows for precise manual control of the loudness changes over time for individual audio channels, enabling our model to effectively address the intricate correlation of video and audio in real-world Foley workflows. Tri-Ergon is capable of creating 44.1 kHz high-fidelity stereo audio clips of varying lengths up to 60 seconds, which significantly outperforms existing state-of-the-art V2A methods that typically generate mono audio for a fixed duration.
SocialMind: LLM-based Proactive AR Social Assistive System with Human-like Perception for In-situ Live Interactions
Dec 05, 2024

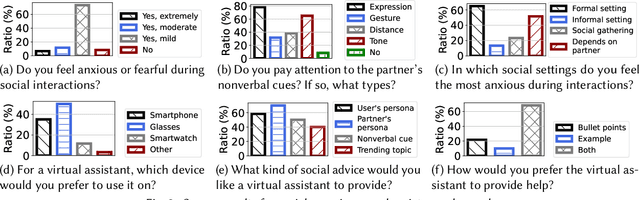
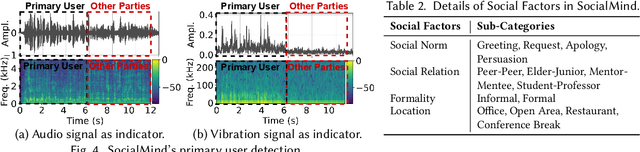
Social interactions are fundamental to human life. The recent emergence of large language models (LLMs)-based virtual assistants has demonstrated their potential to revolutionize human interactions and lifestyles. However, existing assistive systems mainly provide reactive services to individual users, rather than offering in-situ assistance during live social interactions with conversational partners. In this study, we introduce SocialMind, the first LLM-based proactive AR social assistive system that provides users with in-situ social assistance. SocialMind employs human-like perception leveraging multi-modal sensors to extract both verbal and nonverbal cues, social factors, and implicit personas, incorporating these social cues into LLM reasoning for social suggestion generation. Additionally, SocialMind employs a multi-tier collaborative generation strategy and proactive update mechanism to display social suggestions on Augmented Reality (AR) glasses, ensuring that suggestions are timely provided to users without disrupting the natural flow of conversation. Evaluations on three public datasets and a user study with 20 participants show that SocialMind achieves 38.3% higher engagement compared to baselines, and 95% of participants are willing to use SocialMind in their live social interactions.